在加拿大
对于中国城市,人们有许多归类,一线城市、二线城市、超一线城市、新一线城市。每一座城市,都或多或少地在一些城市榜单上暂居前列,并声称自己才是中国城市的Top N。一些城市,有时成为人们“逃离”的对象,有时又被纷纷“逃回”……在纷杂的各类定性比较重,我们始终无法回避一个问题——中国哪座城市对人才最具吸引力?
我们使用了一个大型公开的人才履历数据库,试试从不同角度来测算这个问题。
该数据库记录了近十多年求职者用户的履历变化情况,包括毕业学校,每一份工作的公司名称、地点、职位等。比起各类用间接指标构建的指数来说,劳动者的实际就业去向,将能够更真实地呈现出每个城市的不同吸引力。为了保证研究更有时效性,我们选用了其中近五年的数据(约70万份履历),进行城市吸引力的计算。
按照履历数量
首先,我们用一张图,列出工作履历所在地点的前20名。注意,该图中我们的分析范围为全国主要城市,包括了香港特别行政区和台湾地区,这两个城市在其他数据库中几乎不会被覆盖到。
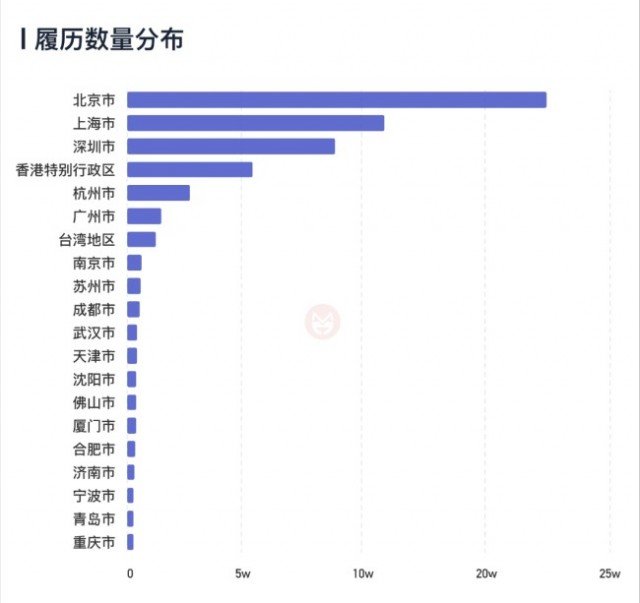
从图中可以看到,北京、上海、深圳排名整个大中华地区的前三名,香港紧随其后,之后是杭州、广州,台湾地区名列第七。
当然,如果我们只是看这一项分布就得出城市吸引力的排名,这个排名未免也太简单了。
每一项数据都存在自己的弱点,比如这一份数据就可能存在着比较大的“大都市偏误”。例如北京、上海两地的GDP不相上下,但北京的履历数就要高于上海许多。广州、杭州等地的GDP均接近北京、上海的一半,但在该数据中,广州和深圳的工作岗位履历数却不到北京、上海的七分之一。
在样本本身有选择性偏误的情况下,如何从中获取有效的信息,对城市吸引力进行排名?
观察名校毕业生首次就业流向
一种可能是,只有在某些地点的人会选择使用履历数据库,因此工作地点分布存在着较强的选择性问题。但有一项数据可以帮助我们尽量消除这样的选择性问题。
这个数据就是每个人所在的学校。
清华大学、北京大学、华东五校(复旦大学、上海交通大学、浙江大学、南京大学、中国科学技术大学)以及中国人民大学,简称“清北华五人”,这8所学校在各项排行榜上都较为领先,且招生对象遍布全国,本地学生比例更低。当我们使用这些学校的学生分布时,可以在很大程度上消除城市排名中的地域自选择性。
打个比方,如果我们使用上海人的工作地点来排序城市吸引力,那么上海毫无疑问将成为全国第一。但如果我们使用北京大学的毕业生在北京以外的选择,复旦大学的毕业生在上海以外的城市的选择,其排序就将更具有说服力。
我们将前一张列表中中国前20名的城市进行了排序,结果如下:
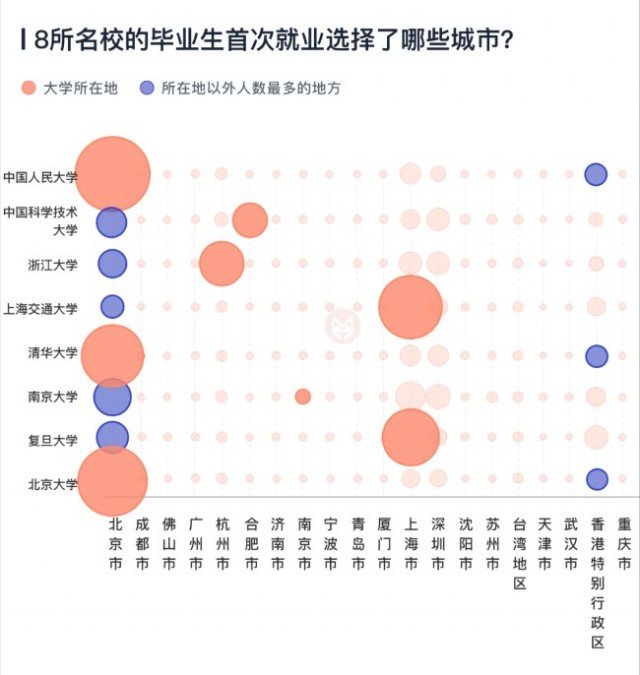
在上表中,北京大学、清华大学和中国人民大学在北京、复旦大学和上海交通大学在上海、浙江大学在杭州,以及中国科学技术大学在合肥,这七所学校的学生留在当地的毕业生占比都是最高的。而南京大学虽然在南京,但毕业后最多的学生仍然去向北京,留在南京的比例仅在这20座城市中排名第五。
我们可以进一步计算每座城市在每所学校的排名,并将其所在城市去除后计算一个“非大学所在城市排名”,列表如下:

上表显示,从名校毕业生流向的角度来看,中国最吸引人才的城市仍然是北京、上海、香港、深圳、杭州。
与履历数量排名相比,香港和深圳的位置交换了,深圳虽然有更高的工作占比,但对于清北华五人学校的学生来说,其吸引力还是略逊香港一筹。例如北京大学、清华大学和中国人民大学三所学校的毕业生,毕业的首选均是在北京工作,而次选就是香港,随后是上海,第四名才是深圳。
台湾地区、广州、苏州、南京和成都排名6-10位。
就业地变动的引力模型
使用大学生毕业后的第一份工作,确实能够去除一定的自选择性,但需要注意的是,中国的大学分布原本就是高度地区不均等的,北京和长三角集中了绝大多数的优秀大学,即使去除了大学所在地,他们仍然会选择周边的城市,这是无法通过控制大学非本地的就业选择来去除的。
但是,该履历数据还提供了另一项有用的信息来帮助我们,那就是换工作的信息。第一份工作和第二份工作之间,存在什么地区差异?例如第一份工作在上海,第二份工作换到了北京;或者第一份工作在深圳,第二份工作换到了成都等。
换工作时,城市间的吸引力,就像是天体之间的引力一样是可以通过其相互之间作用力的大小计算出来的。万有引力公式如下:
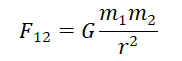
将其两边取对数后,得到:
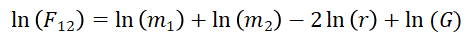
将其中的作用力换成人才流动,质量换成人才存量后,便得到了标准的人才流动引力模型估计方程,其估计式如下:

通过上式我们可以估计不同系数,我们可以从流动的工作人才中扣除两地人才的吸引效应以及两地的距离效应后,剩下的部分(地点哑变量的系数)就是不同城市的“净吸引力”大小,表示这个城市和其他城市相比,在控制了经济总量和距离的基础上,仍然能够吸引更多的人口流入。城市的吸引力排序如下:
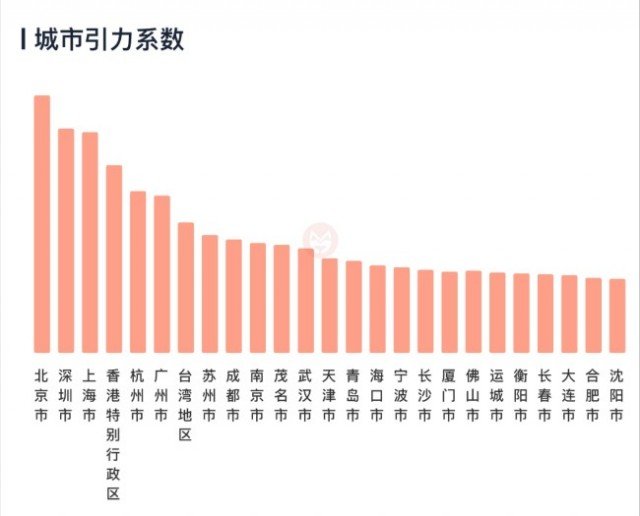
上图列出了城市吸引力的前25名。从图中看,中国的城市吸引力前5名仍然是北京、深圳、上海、香港、杭州。广州、台湾地区、苏州、成都、南京排名6-10名。
11名之后的排序出现了较大的变化,如茂名、海口、长沙、运城、衡阳等地出现在了吸引力的前20名中,这些城市虽然在GDP总量或者产业上没有其他城市那么强大,但是可能在宜居性上更胜一筹,从而能够吸引人们在更换工作时加入其中。
值得注意的是,在前几张表格中始终能够排名接近前十名的天津市,在该表中消失了,甚至在前25名都没有出现。这意味着虽然天津可以吸引大学生作为第一份工作的选择,但人们在更换第二份工作时,天津不太会成为一个备选项。
城际双向流动的非传递性排序
使用引力模型,我们的确能够计算城市的吸引力并加以排序,但引力模型的系数包含了太多影响因素,难以进行解释,同时,引力模型测算的结果高度依赖模型设计以及其中的“质量”变量的设置。用GDP来当做“质量”,用总人口当做“质量”,以及用工作人口当做“质量”,在引力模型中将会得出完全不同的结果。
如何使用城市之间的劳动力流量来获取更多的信息,并获得更稳健的结果呢?
一个朴素的想法是,利用一对城市之间双向流动的情况进行测算。举个例子,有A、B两座城市,每年从A城市向B城市迁移10人,同时从B城市向A城市迁移20人,且两者之间的比例高度稳定,不正说明A城市比起B城市来说更具有吸引力吗?
进一步推广开来,对A城市来说,我们可以依次去计算对于B城市、C城市、D城市……等等的相互之间流动人口,当从B、C、D……城市迁入A城市的人才大于从A城市迁去B、C、D城市的人才时,意味着A城市比起B、C、D城市更具有吸引力。那么只要计算每一个城市的吸引力大于剩下城市中的几个,我们就能算出一个城市吸引力的“非传递性”排名。
所谓的“非传递性”,指的是排名中可能会出现A大于B,B大于C,但C也大于A的情况,在城市人才流动中常常会出现这样的“循环”,但我们可以计算每个城市在相对于其他所有城市的排序中排名更高的数量。

上表列出了从每一个城市到另一个城市迁入、迁出人才的比值。例如上表的第三行第一列等于1.2,表示从北京迁往上海的人才是从上海迁往北京的人才的1.2倍。对应地,上表的第一行第三列就等于0.83,表示从上海前往北京的人才是从北京迁往上海的人才的0.83倍,即前者的倒数。
对于每一个城市,我们纵向计算其大于1的个数,便能够计算出这个城市的吸引力比其他多少城市要更大了,其结果列表如下:
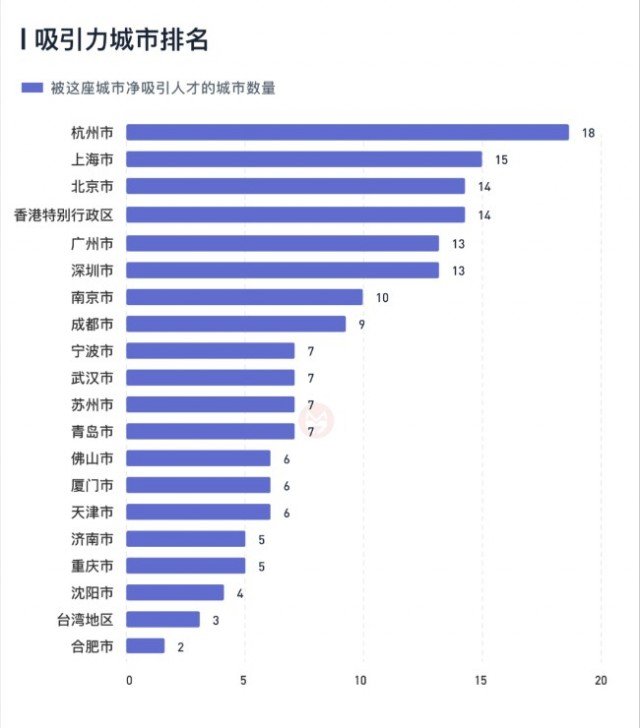
上表可以看到,在这样的排序下,城市吸引力的第一名变成了杭州。除了厦门以外,其他所有城市迁往杭州的人才数均要大于杭州往其他城市迁移的人才数。
上海市排名第二,只有广州、杭州、武汉、苏州和青岛吸收来自上海的人才要大于上海吸收这些城市的人才,其他城市均被上海净吸引人才。并列第三名是北京与香港特别行政区。广州和深圳并列第五名。南京、成都分别排名第七与第八。随后宁波、武汉、苏州和青岛四座城市并列第九。
值得注意的是,台湾地区在之前的排名中虽然还算靠前,但在非传递性排序的城市排名中成为了倒数第二名,几乎所有城市都从台湾地区吸引的人才都要大于台湾地区从这些城市吸引的人才。
写在最后
城市间的吸引力排序,是一项复杂而主观性很强的工作。使用不同的方法,我们关注的是不同的侧重点,因而往往会得到完全不同的结果。
但无论如何排序,城市吸引力的前几名依然保持不变——北上广深杭+香港,总能在中国城市吸引力中排名前六。值得一提的是,香港的吸引力在近些年来虽然有所下降,但在数据中依旧呈现出了对人才的强劲拉力。而一些城市,例如台湾地区,天津等,其排名则渐渐落后于存量工作岗位的分布,呈现出被其他城市“虹吸”的现象。
更有意思的是,城市之间的吸引力其实存在着“石头剪刀布”效应。
例如:
厦门从杭州吸引的人才大于杭州从厦门吸引的人才,
杭州从上海吸引的人才又大于上海从杭州吸引的人才。
但厦门从上海吸引的人才,反而又要小于上海从厦门吸引的人才。
这个现象其实说明,城市对于人口而言,也许并不存在一个绝对意义上的最优解。就是在这样A好于B、B好于C但C又好于A的鄙视链循环中,城市间的人口流动才会源源不断,如流水一般,活跃了每一个城市。
·加拿大新闻 新款本田飞度怎么样?外观造型个性运动,车辆配置还需提升
·加拿大新闻 加拿大保守党确认:博励治下届大选需另寻选区,席位还给原议
·加拿大新闻 甚么样的豪宅开价竟高过政府估价1100万元?
·加拿大新闻 加拿大华人买房踩雷:被追缴7万税,95%写加拿大人名下也没用
·加拿大新闻 快检查!多伦多知名华人超市出售的牛肉紧急召回,12家门店全
·中文新闻 除一个城市外,澳大利亚所有主要城市的房价均创历史新高
·中文新闻 雷切尔被称为“有史以来最好的叛徒”,因为她和史蒂芬在戏剧













